Publications
Check the latest through Google Scholar.
2026
- CVPR 2026
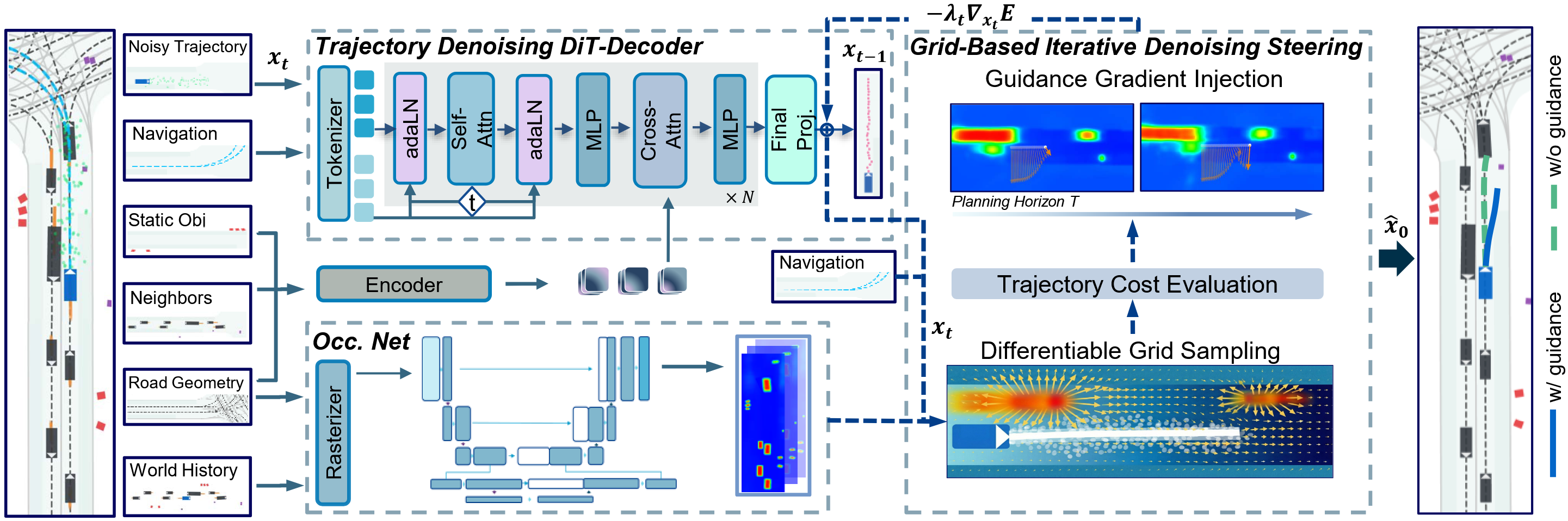
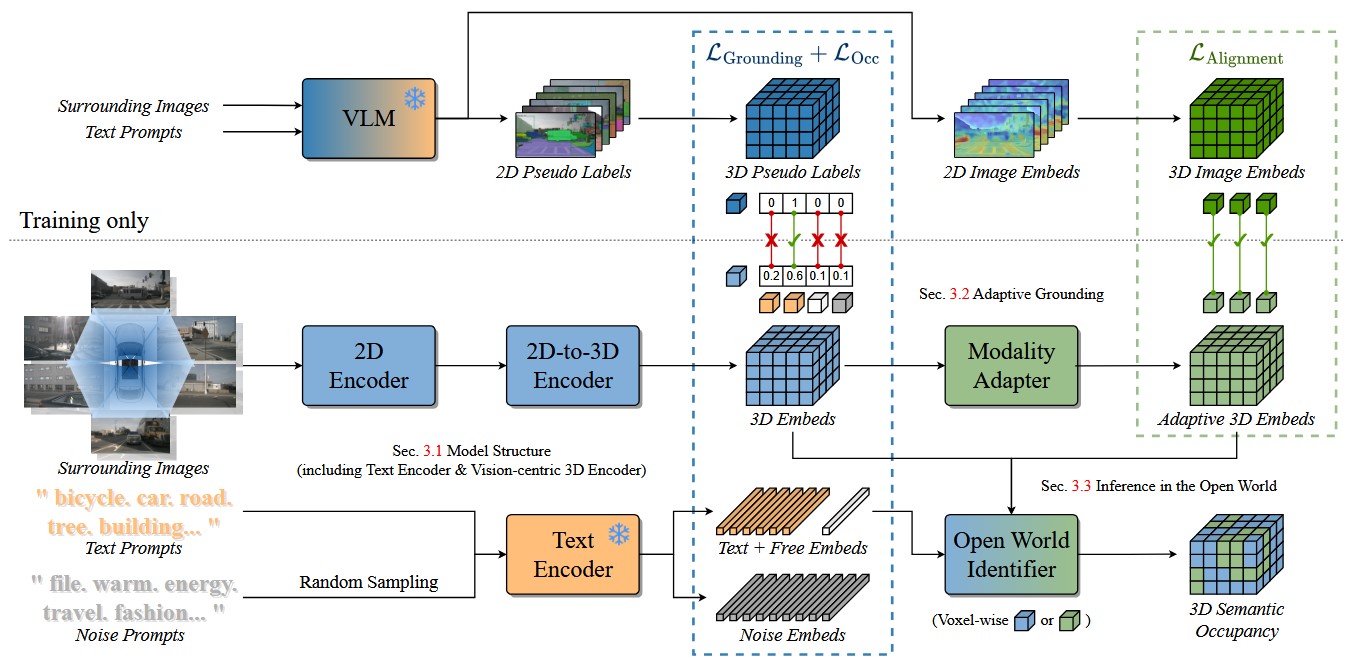
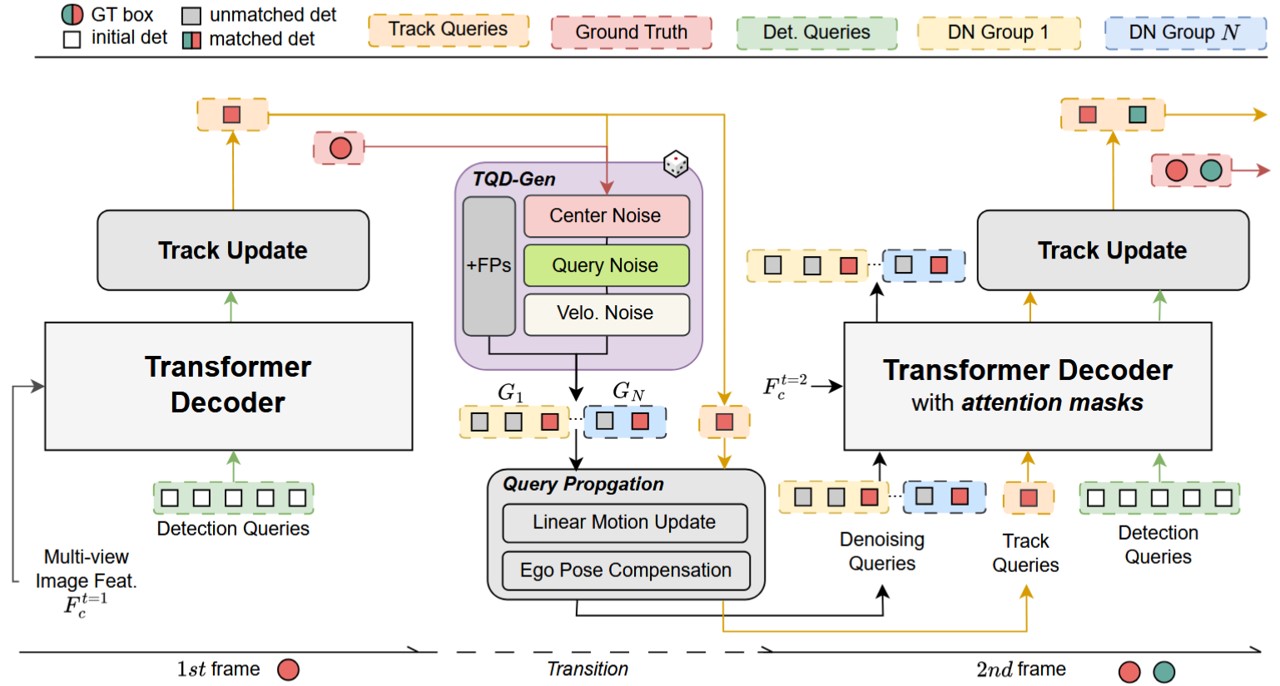
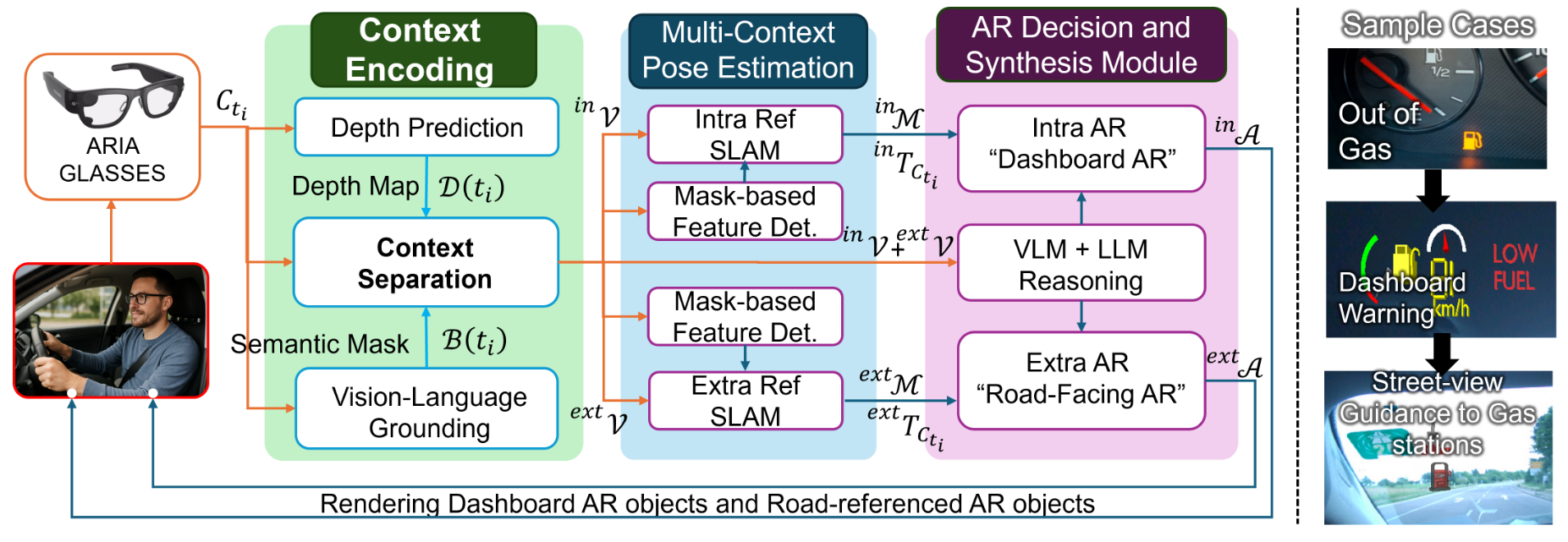
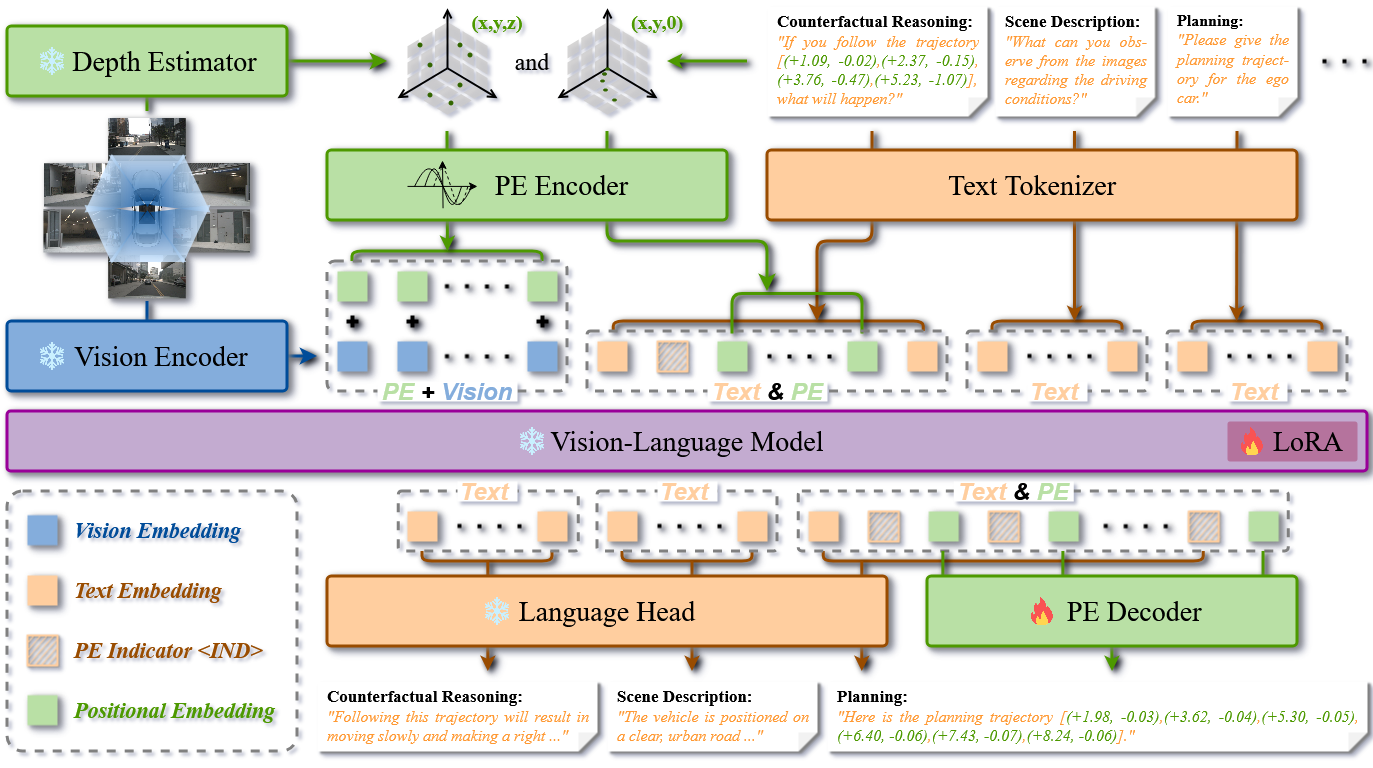 SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous DrivingInfusing explicit spatial representations into vision-language models for robust autonomous driving with 3D spatial reasoning.IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous DrivingInfusing explicit spatial representations into vision-language models for robust autonomous driving with 3D spatial reasoning.IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026 - ICML 2026 (Highlight)
- IROS 2026
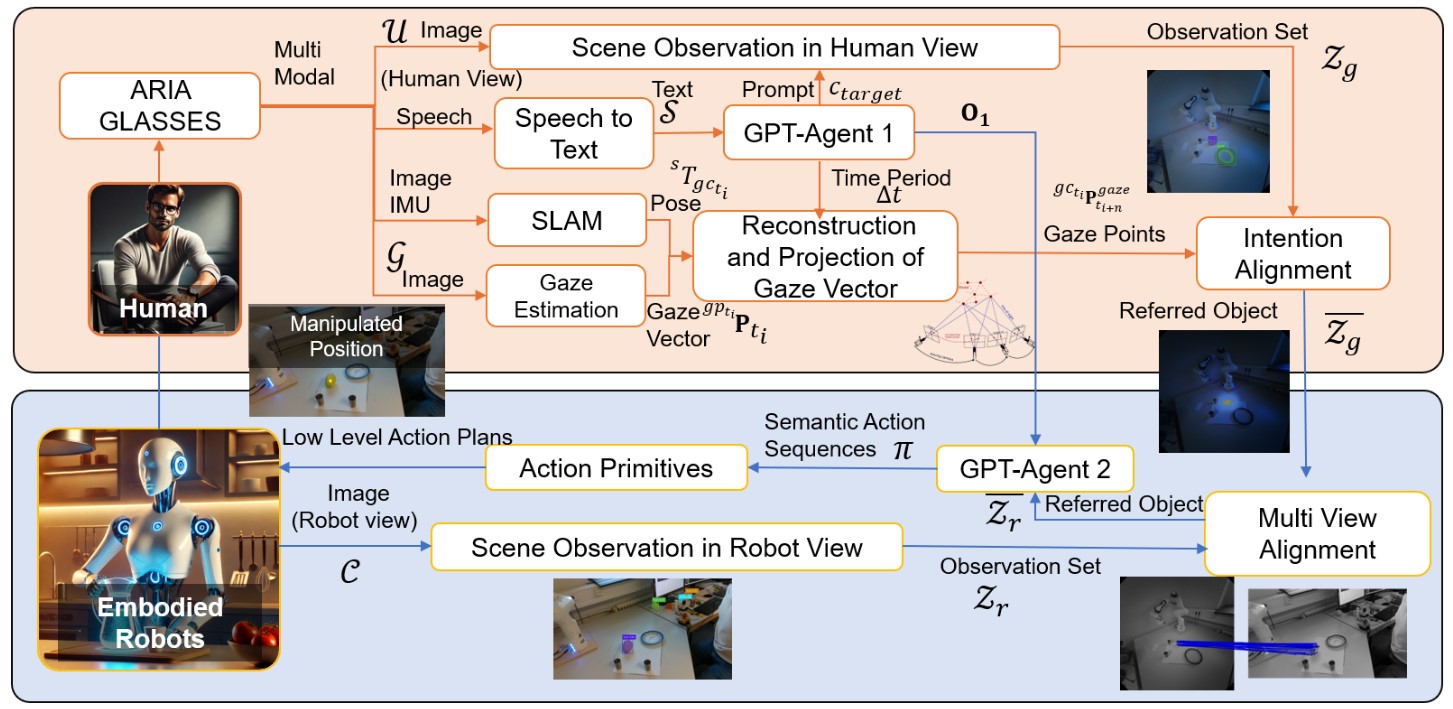
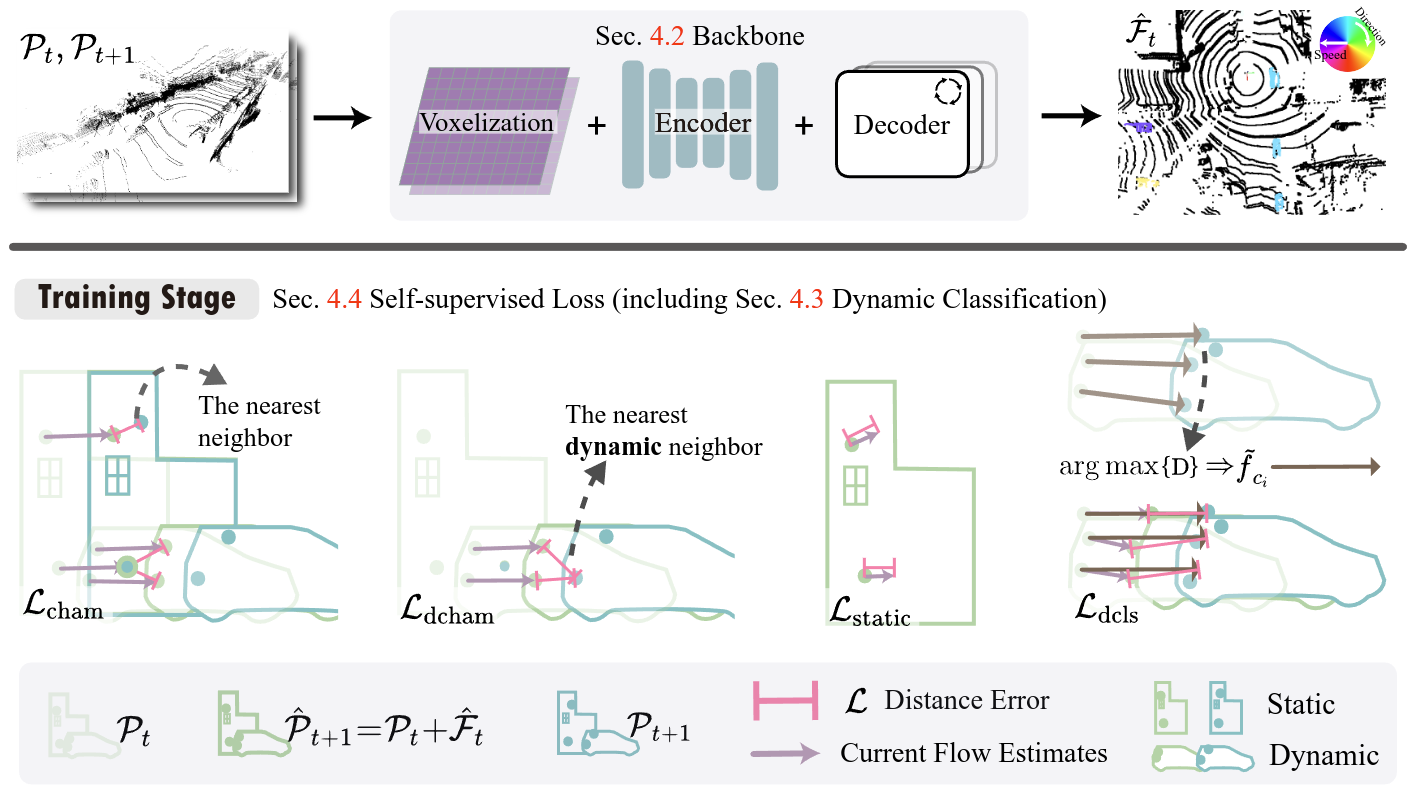
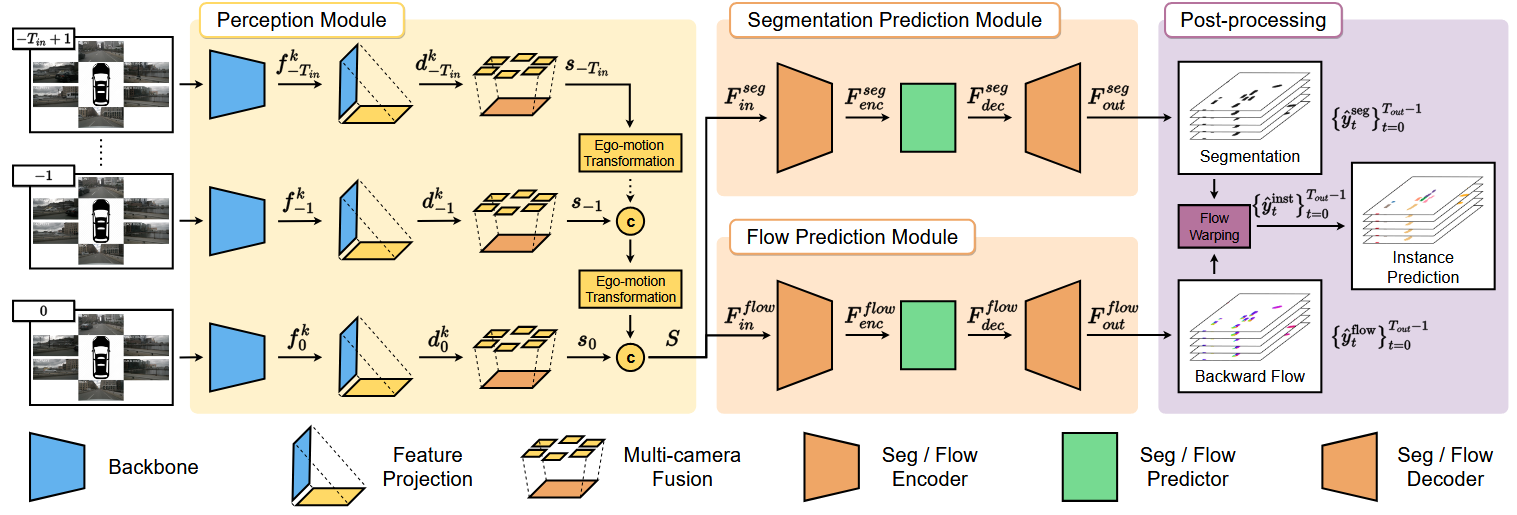
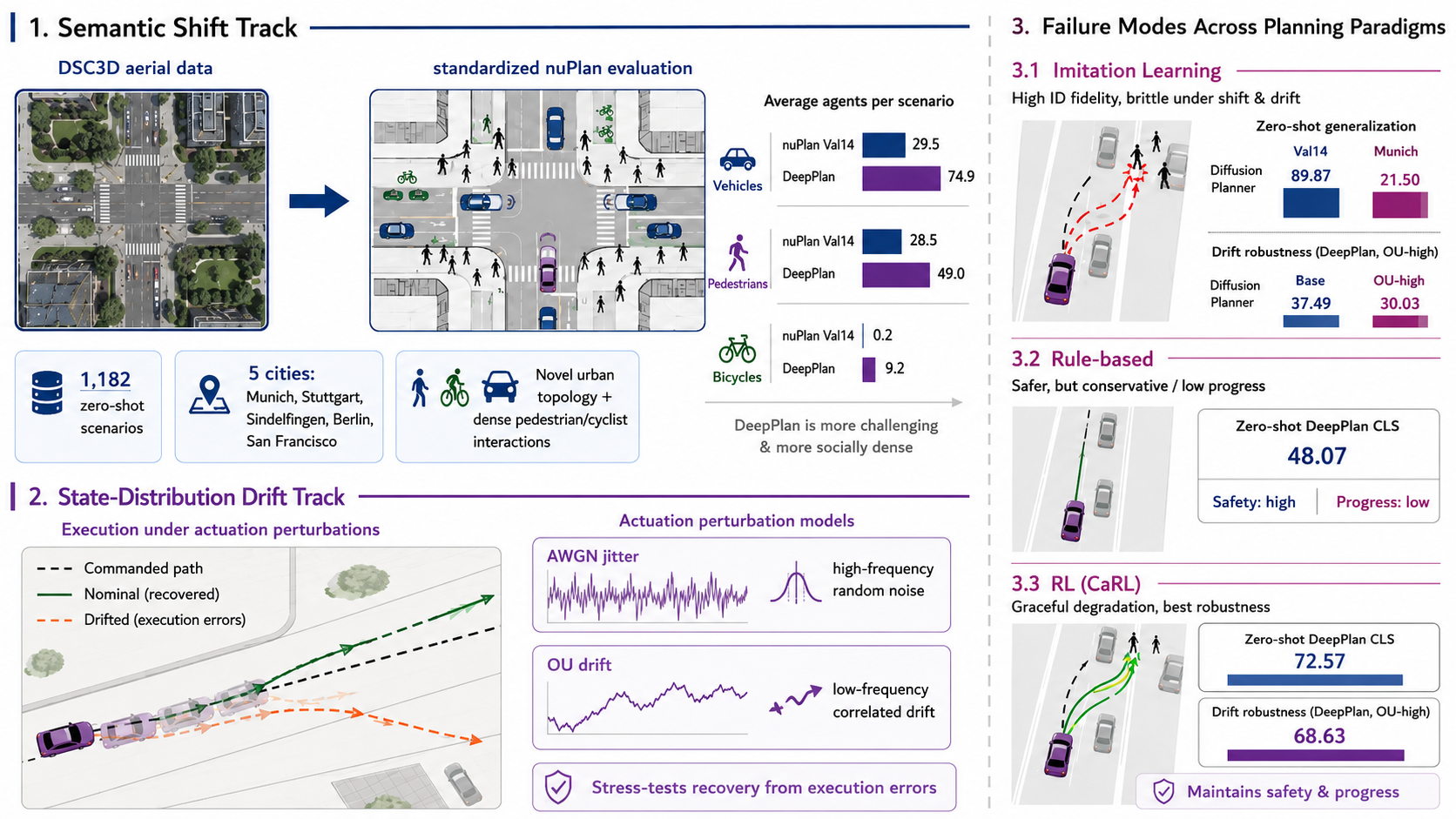 Shift & Drift: A Zero-Shot Benchmark for Generalizable and Robust Autonomous Driving Motion PlanningZero-shot dual-track benchmark stress-testing motion planners under semantic shift and state-distribution drift in closed-loop driving.IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026
Shift & Drift: A Zero-Shot Benchmark for Generalizable and Robust Autonomous Driving Motion PlanningZero-shot dual-track benchmark stress-testing motion planners under semantic shift and state-distribution drift in closed-loop driving.IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026 - EMBC 2026
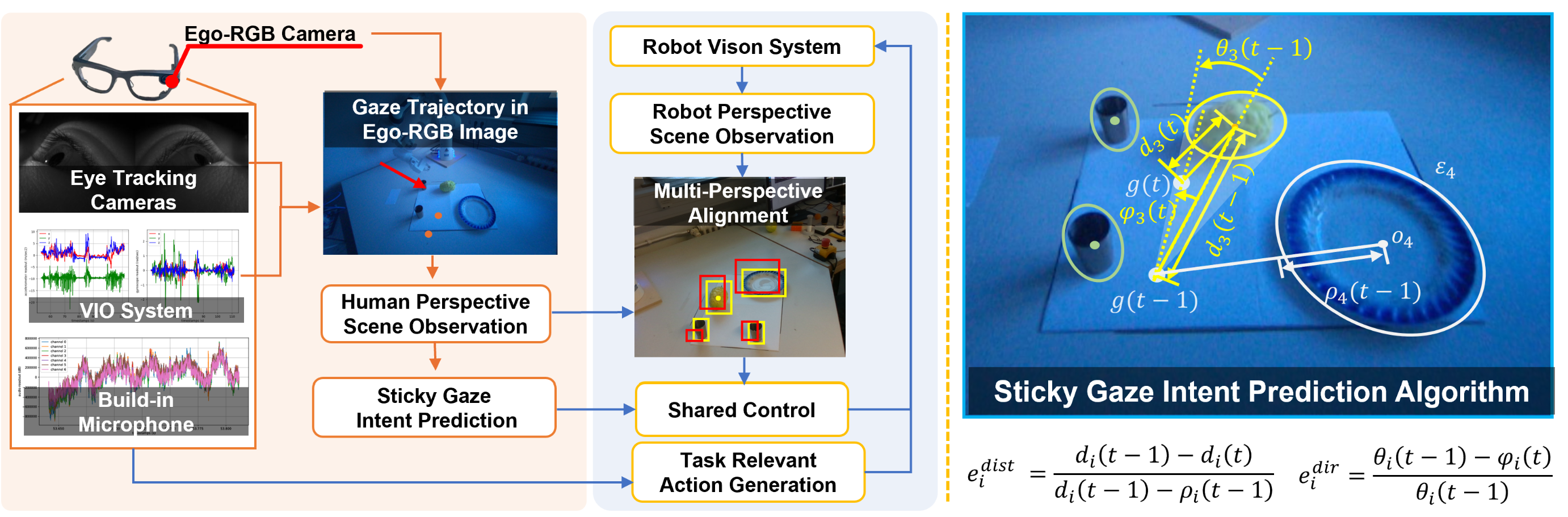
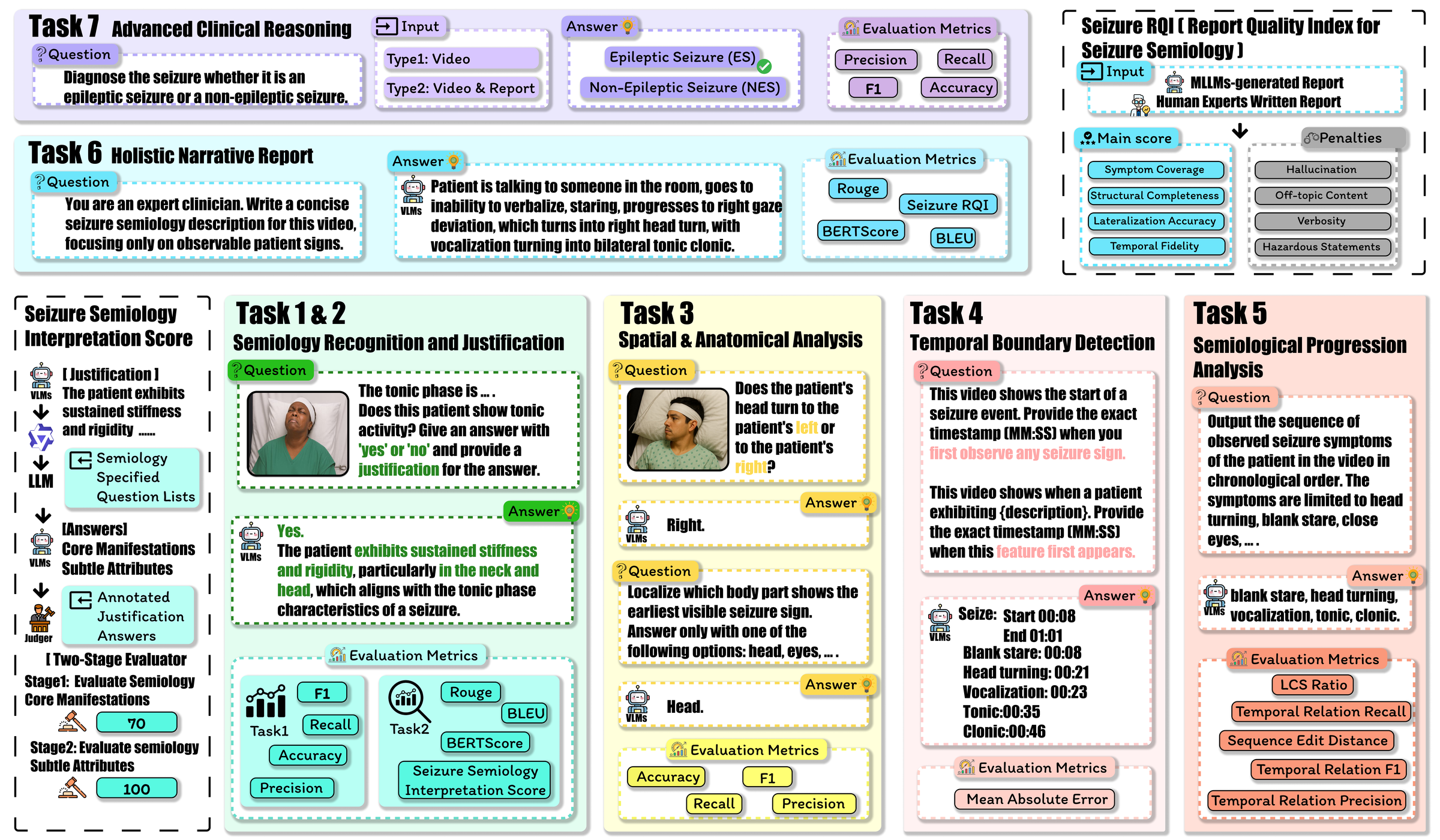
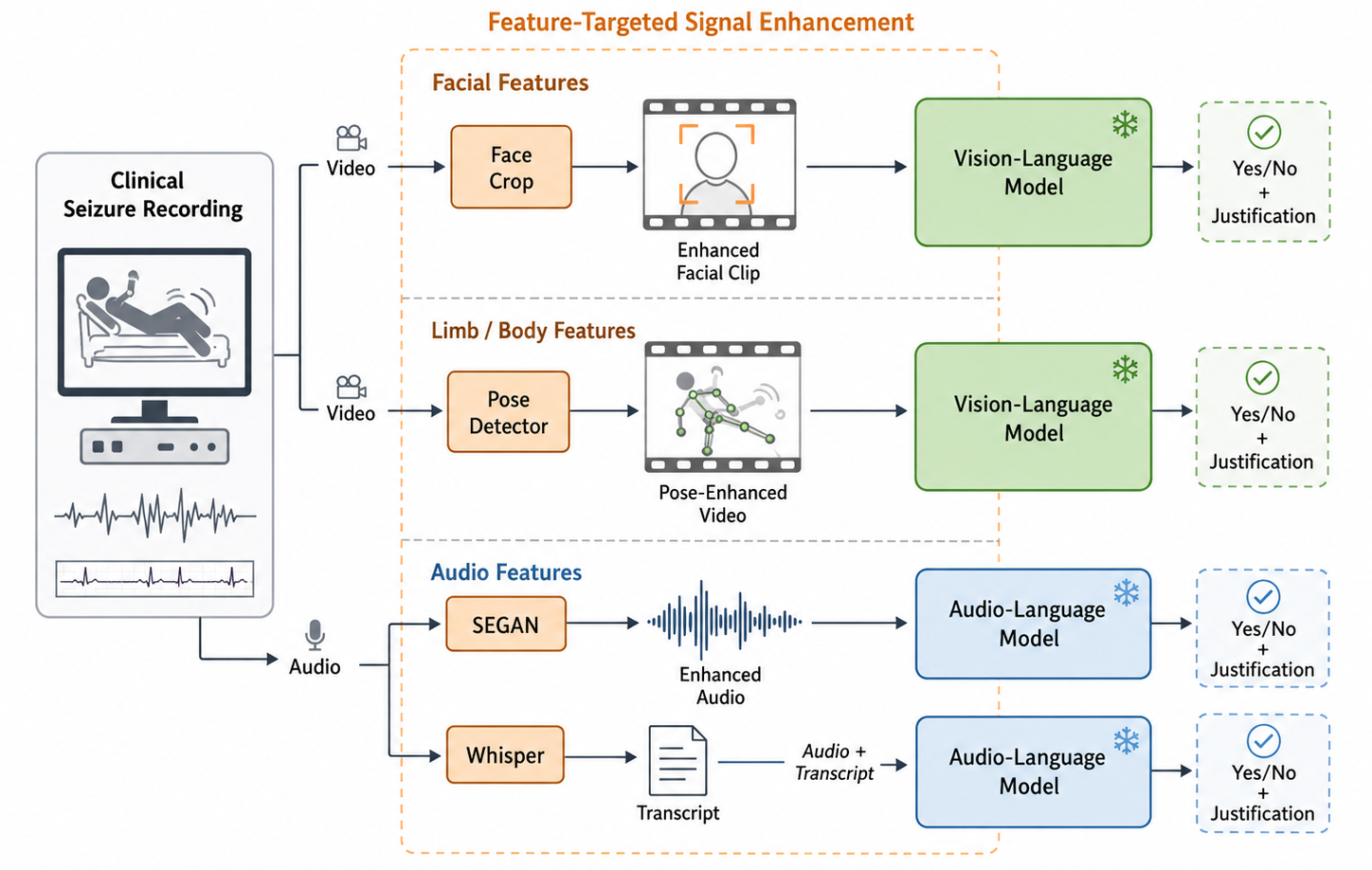 Can Multimodal Large Language Models Understand Pathologic Movements? A Pilot Study on Seizure SemiologyPilot study evaluating multimodal large language models for interpretable pathological movement recognition in seizure videos.Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2026
Can Multimodal Large Language Models Understand Pathologic Movements? A Pilot Study on Seizure SemiologyPilot study evaluating multimodal large language models for interpretable pathological movement recognition in seizure videos.Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 2026